Нейросетевое распознавание классов в режиме реального времени
Аннотация
Дата поступления статьи: 01.01.2013Работа посвящена проблеме разработки теоретических и прикладных основ применения интеллектуальных технологий для продуктивного извлечения знаний из массивов данных для принятия решений в реальном времени. Разработана методика построения ускоряющего алгоритма при одновременном контроле за допустимой адекватностью модели, позволяющего обучать нейросетевые модели в темпе реального времени в пределах заданных рисков. Предложен ускоряющий алгоритм и построены нейросетевые модели на основе стандартного эмулятора, обеспечивающие требуемую продуктивность при обработке массива входных данных. в рамках заданных ограничений.
Ключевые слова: нейроэмулятор, ускоряющий алгоритм, каскадная схема, обучающая выборка, градиентный спуск, обратное распространение ошибки
05.13.01 - Системный анализ, управление и обработка информации (по отраслям)
Введение
Адекватная математическая модель, аналитически связывающая входные факторы ССТС с выходными индикаторами её состояния, является основой построения оптимальной системы принятия решений. Однако в условиях большой размерности вектора входных данных и сложности взаимосвязей с индикаторами состояния объекта, построить адекватную многомерную зависимость сразу для всего массива данных, как правило, не удается [1,2]. Поэтому нахождению многофакторной зависимости, как решение задачи многомерной регрессии, должна предшествовать процедура структурирования исходных данных с целью формирования однородных подмножеств. В этом случае зачастую удается добиться заданных границ производительности при построении модели регрессионного анализа для каждого из полученных подмножеств. Вместе с тем, формирование однородных подмножеств, в ряде случаев [3], совпадает с процедурой описания классов, в пространстве имеющихся признаков исследуемого объекта. Это особенно очевидно в задачах дихотомии (больной - здоровый, кондиция -фальсификат, успешный - лузер и т.п.). Тогда в динамичном, быстро меняющемся признаковом множестве, актуальна задача автоматического построения алфавита классов в режиме реального времени. В этом заинтересована, например, такая структура, как ситуационный центр быстрого реагирования [4]. Решение задачи автоматизации процедур, обеспечивающих распознавание классов в реальном времени, целесообразно осуществлять в нейросетевом формате в среде нейроэмуляторов, например, пакета технического анализа Statsoft.
Постановка задач
Формально построение математической модели внутренней структуры индикаторов состояния объекта на основе исходных данных входного множества факторов сводится к отображению пространства факторов на пространство состояний с заданной надежностью и точностью как в прямой задаче распознавания:
![]() (1)
(1)
так и в обратной (адаптация множества признаков под целевое состояние объекта)
![]() (2)
(2)
путем нахождения соответствующих функционалов преобразования F и F0,
где ![]() – множество выборок признаков описания состояния объекта;
– множество выборок признаков описания состояния объекта; ![]() – множество выборок признаков описания целевого состояния объекта;
– множество выборок признаков описания целевого состояния объекта; ![]() – верифицированное выходное значение функции регрессии;
– верифицированное выходное значение функции регрессии; ![]() – требуемое выходное значение функции регрессии.
– требуемое выходное значение функции регрессии.
При конечном массиве обучающих выборок ![]() , выбранной функции расстояния между примерами
, выбранной функции расстояния между примерами ![]() (эвклидово расстояние), необходимо на первом этапе разделить массив данных на непересекающиеся подмножества, так, чтобы каждое состояло из объектов, близких по метрике
(эвклидово расстояние), необходимо на первом этапе разделить массив данных на непересекающиеся подмножества, так, чтобы каждое состояло из объектов, близких по метрике ![]() , а объекты разных подмножеств существенно отличались между собой, то есть оптимизировать суммы:
, а объекты разных подмножеств существенно отличались между собой, то есть оптимизировать суммы:
![]() (3)
(3)
![]()
где ![]() – множество выборок признаков описания инвестиционных состояний;
– множество выборок признаков описания инвестиционных состояний; ![]() – множество номеров кластеров;
– множество номеров кластеров; ![]() – множества значений входных факторов и номеров классов; h, j = 1,2,…,K – средние значения в кластерах;
– множества значений входных факторов и номеров классов; h, j = 1,2,…,K – средние значения в кластерах; ![]() – расстояние между объектом и центром кластера;
– расстояние между объектом и центром кластера; ![]() – расстояние между центрами кластеров.
– расстояние между центрами кластеров.
Алгоритмическая реализация группирования однородных данных на входе по выбранной метрике осуществляется решением задачи классификации без учителя в нейросетевом формате [1,2]. Что является одной из обеспечивающих распознавание процедур. Формализуем и решим эту задачу в нейросетевой среде.
Рассмотрим пространственный вариант набора входных факторов гипотетического исследуемого объекта из m точек ![]() в n-мерном пространстве. Необходимо разбить множество точек
в n-мерном пространстве. Необходимо разбить множество точек ![]() на k кластеров согласно условия (3) для выбранной меры близости (квадрат евклидова расстояния). Для этого необходимо найти k точек
на k кластеров согласно условия (3) для выбранной меры близости (квадрат евклидова расстояния). Для этого необходимо найти k точек ![]() таких, что,
таких, что, 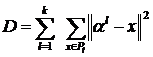 минимально.
минимально.
Решение задачи
-
Зададимся набором начальных точек
 из исходного множества факторов исследуемой ССТС и разобьем множество точек
из исходного множества факторов исследуемой ССТС и разобьем множество точек 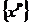 на k кластеров по правилу
на k кластеров по правилу 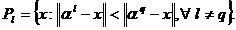
-
По полученному разбиению вычислим новые точки
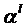 из условия минимальности
из условия минимальности 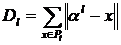
-
Обозначим число точек в i-ом кластере через
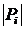 .
. -
Запишем решение выбора точек на втором шаге алгоритма в виде
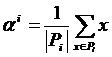
|
|
-
Выполняем процедуры 1-3 алгоритма до тех пор, пока набор точек
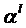 не перестанет изменяться.
не перестанет изменяться. -
Фиксируем сеть способную для произвольной точки x вычислить квадраты евклидовых расстояний от этой точки до всех точек
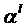 и отнести ее к одному из k кластеров.
и отнести ее к одному из k кластеров. - Ответом является номер нейрона, выдавшего минимальный сигнал.
Созданные для каждого из кластеров отдельные нейронные сети, позволяют получить физическую модель связи входных факторов с индикаторами состояния объекта. При этом индикаторы могут соответствовать как текущему состоянию так и целевому.
Таким образом, технология формирования компактных, однородных подмножеств во входных данных алгоритмически формализована и может быть реализована существующими инструментальными средствами пакетов технического анализа [3].
Таким образом, после группировки входных данных как компактных множеств в многомерном пространстве на основе выбранной метрики близости, новые наблюдения можно классифицировать по принадлежности к тому или иному кластеру с минимальным значением меры близости. Это эквивалентно, для решаемой задачи, процедуре описания классов на языке их информативных признаков и является следующей обязательной, обеспечивающей распознавание, процедурой.
Верифицированное заключение (при наличии времени) может быть получено с привлечением предметного специалиста. Следующей обязательной процедурой является выбор и формализация решающего правила.
Формализация решающего правила
В условиях многомерности входных факторов, неполноты данных о их взаимном влиянии, неопределенности исходной информации целевые критерии для решения задач поддержки принятия решений, как правило, формализуются в виде лингвистических переменных или в виде правил логического вывода относительно эффективности функционирования объекта. Массив выборок ![]() совместно с соответствующим массивом классов
совместно с соответствующим массивом классов ![]() используется для обучения в задаче распознавания актуальных состояний объекта исследования. Эту процедуру можно выразить в требовании, а именно оптимизировать функционал процесса распознавания текущего состояния объекта:
используется для обучения в задаче распознавания актуальных состояний объекта исследования. Эту процедуру можно выразить в требовании, а именно оптимизировать функционал процесса распознавания текущего состояния объекта:
![]() (4)
(4)
где ![]() – расстояние между объектами (признаками) внутри класса по заданной метрике, вычисляется с помощью следующего выражения:
– расстояние между объектами (признаками) внутри класса по заданной метрике, вычисляется с помощью следующего выражения:
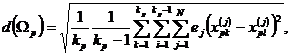 (5)
(5)
![]() – расстояние между объектами (признаками) в разных классах по заданной метрике, вычисляется с помощью следующего выражения:
– расстояние между объектами (признаками) в разных классах по заданной метрике, вычисляется с помощью следующего выражения:
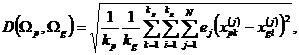 (6)
(6)
![]() – правило отнесения объекта
– правило отнесения объекта ![]() к соответствующему классу;
к соответствующему классу; ![]() – индикатор наличия (отсутствия) признака
– индикатор наличия (отсутствия) признака ![]() ;
; ![]() – множество объектов в классе
– множество объектов в классе ![]() .
. ![]() – заданная метрика. Тогда решение (4) достигается минимизацией (5), максимизацией (6):
– заданная метрика. Тогда решение (4) достигается минимизацией (5), максимизацией (6):
![]()
![]() (7)
(7)
и реализацией преобразования ![]() , в соответствии решающего правила:
, в соответствии решающего правила:
![]() , если
, если ![]() , (8) где
, (8) где ![]() ; h, j = 1,2,…,K – средние значения в кластерах;
; h, j = 1,2,…,K – средние значения в кластерах; ![]() – расстояние между объектом и центром кластера;
– расстояние между объектом и центром кластера; ![]() – расстояние между центрами кластеров;
– расстояние между центрами кластеров; ![]() – множество выборок признаков состояний;
– множество выборок признаков состояний; ![]() – множество номеров кластеров;
– множество номеров кластеров; ![]() .
.
Алгоритмическая реализация решающего правила
- Полагаем все веса элементов равными нулю.
- Проводим цикл предъявления примеров. Для каждого примера выполняется следующая процедура:
-
2.1. Если сеть выдала правильный ответ, то переходим к шагу 2.4.
- 2.2.Если на выходе персептрона ожидалась единица, а был получен ноль, то веса связей, по которым прошел единичный сигнал, уменьшаем на единицу.
2.3.Если на выходе персептрона ожидался ноль, а была получена единица, то веса связей, по которым прошел единичный сигнал, увеличиваем на единицу.
2.4.Переходим к следующему примеру. Если достигнут конец обучающего множества, то переходим к шагу 3, иначе возвращаемся на шаг 2.1.
При этом правило, реализующее приведение выходной ошибки обучения ко входу каждого фактора, имеет строгое математическое описание [1]. Это крайне важно при адаптации входного вектора факторов к целевому состоянию (вектору индикаторов) объекта, поэтому зафиксируем необходимые аналитические соотношения в обозначениях исходной задачи. Ограничимся архитектурой многослойного персептрона и единичной обучающей выборкой. Если мы располагаем целевым вектором индикаторов ![]() , то функция невязки примет вид:
, то функция невязки примет вид:
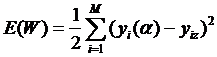 .
.
Модификация синаптических коэффициентов осуществляется на основе градиентного метода:
![]() .
.
Компоненты вектора градиента функции невязки рассчитываются согласно выражений, для расчета элементов многослойного персептрона[1]:
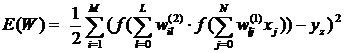
Выходы 1 и 2 слоев нейронов определяются из выражений:
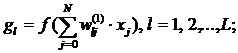
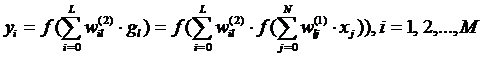
![]()
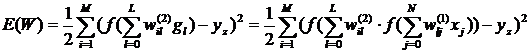
Соотношения для частных производных функции невязки по весам нейронов выходного слоя имеют вид:
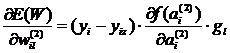 , где
, где 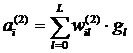 , а
, а
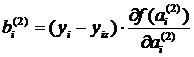 .
.
Тогда соответствующий компонент вектора градиента выглядит следующим образом:
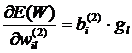 .
.
Компоненты градиента для весов предпоследнего слоя определяются по методике дифференцирования сложной функции [1]:
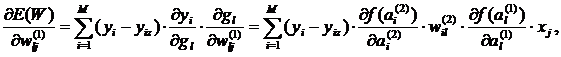
где 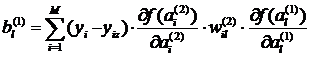 .
.
В компактном виде весовые коэффициенты всего синаптического пространства обученной модели можно представить выражением:
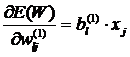 .
.
Анализ приведенных выражений для производных функции ошибки по весам различных слоев сети позволяет получить правило расчета компонентов вектора градиента от функции ошибки по параметрам (весовым коэффициентам) ![]() для любого скрытого слоя нейронной сети:
для любого скрытого слоя нейронной сети:
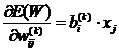 , (9)
, (9)
где ![]() — сигнал на входе в сеть,
— сигнал на входе в сеть, ![]() — величина погрешности обучения
— величина погрешности обучения ![]() , перенесенная с выхода сети к входу (к ее предыдущим слоям).
, перенесенная с выхода сети к входу (к ее предыдущим слоям).
Обеспечение временных ограничений
С учетом того, что по условию задачи эти процедуры ограничены во времени, необходимо реализовать технологию, позволяющую удовлетворить временным ограничениям и допустимым ошибкам на тестовом множестве. Максимальную автоматизацию принятия решений обеспечивает разработка библиотеки программ (On-Line System Neural Network), позволяющей моделировать и обучать многослойные нейронные сети анализа исследуемых объектов в режиме реального времени. Обучение нейронных сетей с точки зрения используемого математического аппарата эквивалентно задаче многомерной оптимизации[1]. В разряд ограничений отводятся: время работы алгоритма и объем требуемых ресурсов. Предлагается следующая структура мер ускорения принятия решений (рис.1.):
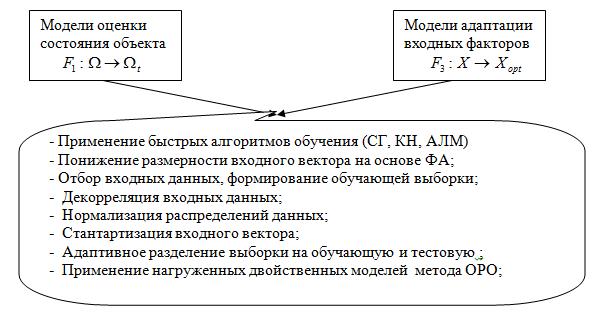
Рис. 1. – Структура ускоряющих процессов
При такой структуре моделирования процессов или объектов, разрешение проблемы оперативного реагирования при принятии решений, сводится к реализации указанных функций путем создания алгоритмов и программ отображения массива входных данных на состояния и динамику их эволюции под влиянием управляющих факторов с учетов директивного времени. Если эта задача имеет решение, то автоматизированная система (АСППР), оперативно (время принятия решения определяется техническими возможностями вычислителей) идентифицирует состояние объекта, прогнозирует его динамику и определяет управляющие факторы, адекватные целевому (требуемому) состоянию.
Для анализа и моделирования базовых отмеченных процессов целесообразно исследовать возможности пакета технического анализа данных StatSoft с нейросетевым модулем STATISTICA Neural Networks [3]. Тогда синтез моделей реализуется в пространстве процедур ускоряющих адаптацию моделей в границах выбранных дисциплинирующих условий.
Логическим продолжением решаемой задачи является комплексное использование всех доступных ускоряющих процедур из пакета Statistica [4] с последующим выделением продуктивных нейросетей из всего ансамбля обученных моделей. Так как все описанные процедуры представляют собой относительно самостоятельные процессы, их совместное использование целесообразно представить в виде циклов в общем алгоритме адаптации:
- Формируем исходные данные. Определяем рабочую и тестовую выборки.
- Определяем директивное время для рассматриваемой предметной области и допустимые ошибки.
- Выбираем ЦФ и адаптируем её к нейросетевому формату.
- Устанавливаем границы возможных изменений элементов входного вектора управляющих факторов.
- Задаем метод обучения в исходном ансамбле моделей с выбором, архитектуры, сложности, функций активации.
- Выбираем класс задач и проводим обучение исходных моделей. Фиксируем время решения и ошибки обучения.
- Сравниваем полученные время и ошибку с директивными для данной задачи (выбранной предметной области). Если условие соответствия выполнено, то переход на шаг 11, если нет – 5, а при условии n = Nmax – переходим на шаг 8. Здесь n и Nmax соответственно порядковый номер исходных методов обучения и их максимальное число.
- Формируем исходные данные для понижения размерности.
- Проводим факторный анализ, ранжируем входы по информативности, исключаем последний элемент мажоритарного ряда. Переходим на шаг 6 и 7. При выполнении условия соответствия – переход на шаг 11, в противном случае – 9. При условии m = Mmax – переходим на шаг 10. Здесь m и Mmax – соответственно, номер исключенного фактора и их максимальное число.
- При наличии времени переходим к экспертным оценкам и после анализа принимаем их как элементы решения данной задачи.
Оценки вероятности используются непосредственно, так как решается задача отнесения набора признаков объекта исследования к наиболее вероятному классу. Так как задача распознавания рассматривается как в прямой трактовке так и в обратной [5], то необходимо учесть имеющие место особенности при решении обратной задачи или задачи распознавания такого набора факторов, который порождает требуемое состояние объекта исследования.
Особенности подстройки входного вектора к требуемому выходу
Для этого случая метод обратного распространения ошибки применяется для подстройки входного вектора через градиент функции ошибки по входным сигналам сети [6]. В основе решения этой задачи лежит приведение ошибки обучения нейронной сети к входному слою нейронов и расчету частных производных градиента функции ошибки по параметрам нейросети и входным факторам. Метод позволяет вычислять производные выходной функции невязки текущего и требуемого состояний объекта по каждому элементу вектора входных факторов и запоминать их. При обратном функционировании эти, ранее вычисленные производные, участвуют в вычислениях градиента функции ошибки по входным сигналам сети.
Эти процедуры выполняются в комплексной схеме нейроуправления с оценками и сохранением в памяти на один такт производных выходных функций каждого элемента всего синаптического пространства нейросети. Технологию инструментальной реализации этих задач проследим на примере известных способов нейроуправления [7].
Адаптивная система контроллера решает задачу отслеживания и сравнения текущего значения выхода с требуемым, заданным вектором уставки. В схемах нейроуправления функции учителя выполняет контроллер, оценивающий невязку текущего и целевого состояния объекта исследования и определяющий сигнал управления Z(t). Обучение – согласно алгоритма обратного распространения ошибки, при этом ошибка сети ![]() определяется разностью уставки и текущего значения выхода эмулятора.
определяется разностью уставки и текущего значения выхода эмулятора.
На рис.2 представлена одна из схем нейроуправления объектом. Нейроэмулятор выполняет функции адаптивной модели управляемого объекта. На его входы поступают текущие и задержанные во времени значения векторов управления ![]() и значения разности между векторами входа и уставки
и значения разности между векторами входа и уставки ![]() . Здесь q - величина шага задержки. Выходом нейроэмулятора является ожидаемое значение выхода управляемого объекта Y*, а также значение вектора ошибки Е для обучения нейроконтролера.
. Здесь q - величина шага задержки. Выходом нейроэмулятора является ожидаемое значение выхода управляемого объекта Y*, а также значение вектора ошибки Е для обучения нейроконтролера.
Величина ![]() представляет вектор ошибки, который используется в алгоритме обучения нейроэмулятора. Ошибка, поступающая в схему контролера поступает сигнал, представляющий отображение ошибки на выходе сети приведенной ко входу нейроэмулятора. Применим каскадную схему двух нейросетей сети, одна из которых имитирует исследуемый объект, а вторая отслеживает и минимизирует интегральную невязку индикаторов текущего и селевого состояний объекта исследования путем формирования соответствующих входных величин [7].
представляет вектор ошибки, который используется в алгоритме обучения нейроэмулятора. Ошибка, поступающая в схему контролера поступает сигнал, представляющий отображение ошибки на выходе сети приведенной ко входу нейроэмулятора. Применим каскадную схему двух нейросетей сети, одна из которых имитирует исследуемый объект, а вторая отслеживает и минимизирует интегральную невязку индикаторов текущего и селевого состояний объекта исследования путем формирования соответствующих входных величин [7].
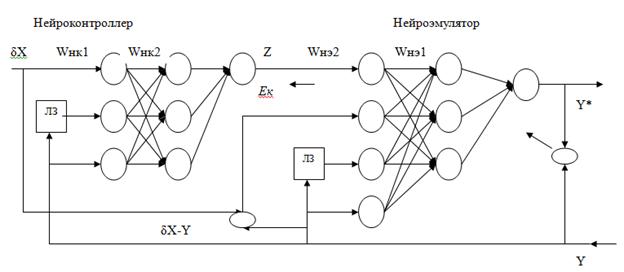
Рис. 2. – Функциональная схема нейроуправления:
Y(t) – текущие значения процесса на выходе; Y(t-q) – текущие значения процесса задержанные на один такт q; U(t) - Y(t) – текущее значение невязки на выходе системы;
Z(t) – текущее управляющее воздействие.
Выходом нейроэмулятора являются текущие значения индикаторов состояния модели объекта Y*(t).
При обучении НЭ осуществляется модификация синаптического пространства путем подстройки весовых коэффициентов в направлении антиградиента невязки [6]. Таким образом, как в прямой так и в обратной задаче распознавания организация и выполнение обучающих процедур базируется на одних и тех же базових функциях (формирование выборки, описание классов, синтез решающего правила, его реализация, верификация результата). Поэтому качество результатов исследования оценим по степени адекватности нейросетевых моделей и достигнутой при этом производительности.
Моделирование градиентного спуска с оценкой частных производных как по параметрам сети так и по входным сигналам, представляющим пространство признаков текущего состояния объекта, показало устойчивую сходимость итерационного процесса обучения сети с приемлемыми для практических задач показателями качества (Рис.3).
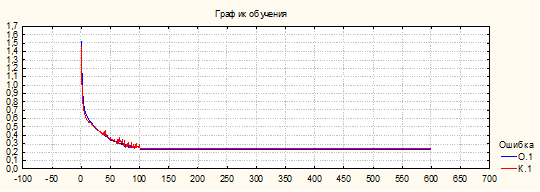
Рис. 3. – График сходимости процесса обучения
Для различных условий моделирования получен ансамбль продуктивных нейросетей, которые могут использоваться в отдельных приложениях на основе их сохранения в формате основного кода.
Результат моделирования распознающего устройства.
В качестве инструмента моделирования использовался модуль Statistika Neural Network пакета технического анализа данных Statistika. Для кластеризации и распознавания состояний объекта исслеждования на основе массива данных формировалась последовательность примеров максимально возможной размерности, формируя словарь признаков. Работа нейросети в режиме кластеризаии позволяет формировать алфавит классов исследуемых объектов на языке этого словаря.
Целевое состояние объекта характеризуется набором значений тех же пространств информативных признаков, которые формируются экспертом предварительно, до начала эксперимента.
Так как каждому классу соответствует свой набор показателей, то процедура классификации объекта свелась к анализу пространства признаков текущего состояния и сравнения результатов анализа с описаниями выбранных классов. В нейросетевом формате задача распознавания классов текущего состояния исследуемого субъекта решлась с использованием известного правил (например, дельта - правила [1]). При наличии двух классов состояний объектов (исправно-неисправно) формирование обучающего множества не вызвало затруднений. Реализована технология моделирования в среде нейроэмуляторов по методике [3,4], что позволило получить ансамбль моделей (Рис.4):
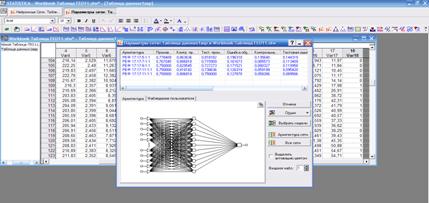
Рис. 4. – Результаты моделирования классификатора
Модели на основе радиально-базовых функций в целом подтверждают вывод о реализуемости базовых функций, но мощность обучающей выборки в приведенных примерах не позволила достичь производительности по условию задачи. Это видно из эксперимента на ансамбле РБФ-сетей (рис. 5.,6)..
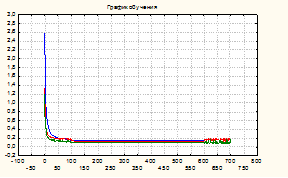
Рис.5. – График обучения модели (Вариант 1)
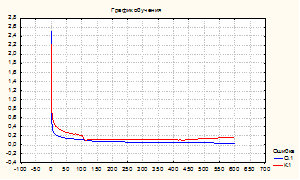
Рис.6. – График обучения модели (Вариант 2)
Производительность моделей (характер динамики обучения) имеет устойчивый вид асимптотических кривых, зависимых от репрезентативности (представительности) обучающего множества (Варианты 1,2), что позволяет улучшать модели при пополнении базы данных.
Как видно из графиков, применение представленной технологии, сокращает время адаптации нейросетевых моделей исследуемых процессов при сохранении их адекватности в допустимых границах и позволило получить устойчивую сходимость итерационного процесса модификации синаптического пространства. Число эпох не превышает нескольких сотен, что в пересчете на общие временные затраты соответствует нескольким десяткам секунд. Массивы привлеченных данных не только из технической области, но и из экономики, медицины позволяют эти временные интервалы привести в соответствие с диррективным временем принятия решений для этих предметных областей и подчеркнуть инвариантность технологии к типам входных данных.
Следует учесть также, что показатели производительности моделей зависят одновременно от мощности обучающей выборки, сложности сети, её типа и архитектуры. Таким образом, получено теоретическое и практическое подтверждение вывода о возможности решения поставленной задачи в реальном времени при сохранении адекватности моделей в заданных границах и корректных допущениях.
Заключение
- Нейросетевой базис для построения однородных подмножеств, как классов состояний объектов на языке их информативных признаков, позволяет автоматизировать реализацию базовые функций распознавания: формирование словаря признаков и алфавита классов, реализацию решающего правила, и адаптацию входов в режиме реального (директивного) времени.
- Инструментальная продуктивная автоматизация базовых функций распознавания возможна и целесообразна с применение стандартных нейроэмуляторов существующих и перспективных пакетов технического анализа данных.
- Адекватность и надежность моделей реализуемых процессов установлена на основе анализа ошибок на тестовом множестве данных, не принимающего участия в обучении, что обеспечивает состоятельность сделанных выводов.
Литература
- Хайкин, С. Нейронные сети: полный курс; пер. с англ. / С. Хайкин ; 2-е изд. – М. : Издательский дом «Вильямс», 2006. – С. 1104.
- Горбань, А.Н. Обучение нейронных сетей / А.Н. Горбань. – М. : Изд-во СССР-США СП «ParaGraph», 1990. – С. 160.
- Боровиков, В.П. STATISTICA NN : техническое описание / В.П. Боровиков. – М.: Мир, 1999. – С. 239.
- Алёшин С.П. Ситуационные центры быстрого реагирования: принятие решений в среде нейроэмуляторов / С.П. Алёшин // Системы управления, навигации и связи – 2011. – № 1 (17). – С. 240 – 247.
- Ляхов А. Л., Алёшин С.П., Бородина Е.А. Нейросетевая модификация текущего пространства признаков к целевому множеству классов. 11- Міжнародна науково-практична конференція « Нейросітьові технології і їх застосування »: Зб. наук. праць / под ред. проф. С. В. Ковалевского. – Краматорск: ДДМА – 2012. – С. 93 – 99.
- Горбань А.Н., Россиев Д.А. Нейронные сети на персональном компьютере // Новосибирск: Наука, 1996.- 276 с.
- Терехов В.А., Ефимов Д.В., Тюкин И.Ю. Нейросетевые системы управления: Учеб. пособие для вузов. – М.: Высш. школа 2002. – 183 с.